
HDFS(Hadoop Distributed File System),前面我们说到,HDFS就像是一个存储数据的仓库,实际上和我们电脑中的文件管理系统一样,都是用来存储数据的。但他们因为需求不同,会有一些设计上的区别。
我们可以把自己当作一个设计大数据存储系统的设计师,想想一个用来存储大量数据的文件管理系统应该有哪些需求:
首先想到的是要安全,即使硬盘坏了,也不能丢失数据,而且也不能造成整个数据系统的崩溃。而且,要有很快的读写速度来保证大量的数据进行读写。
我们来看看HDFS是怎么做的:
- 鸡蛋不能放在一个篮子里
如果我们把数据放在一个地方的话,那硬盘坏了肯定是所有数据都没了,所以HDFS的数据存储是分布式的,他会把数据分散存储在不同的硬盘里,而且互相做备份,即使一个硬盘坏了或者数据损坏,不会影响数据的完整。(分布式存储)
- 当一个硬盘坏了,HDFS可以自动修复丢失的数据。
上一条说到,数据在不同的硬盘中互相备份,当一个机器坏了,HDFS可以检测到,并迅速进行修复,把原本存储在坏机器上的数据从其他机器的备份中修复出来,并存储在其他机器上。
这个特性叫高可用。
我们来分析下这么做的好处,把数据存储在多个机器中,有诸多好处,首先是可以无限拓展存储容量,单个硬盘的存储是有上限的,但架不住人多,硬盘的数量可以有多个,另外单硬盘的读写速度也是有上限的,但架不住人多,大家可以并行读写,这样读写就快了,还有他们之间可以互相备份数据,这样就算某个机器生病请假了,也可以中别的机器中的备份数据来顶一下。
好了,现在我们大概知道HDFS是怎么来存储我们的数据了,现在让我们更具体一些
HDFS的架构
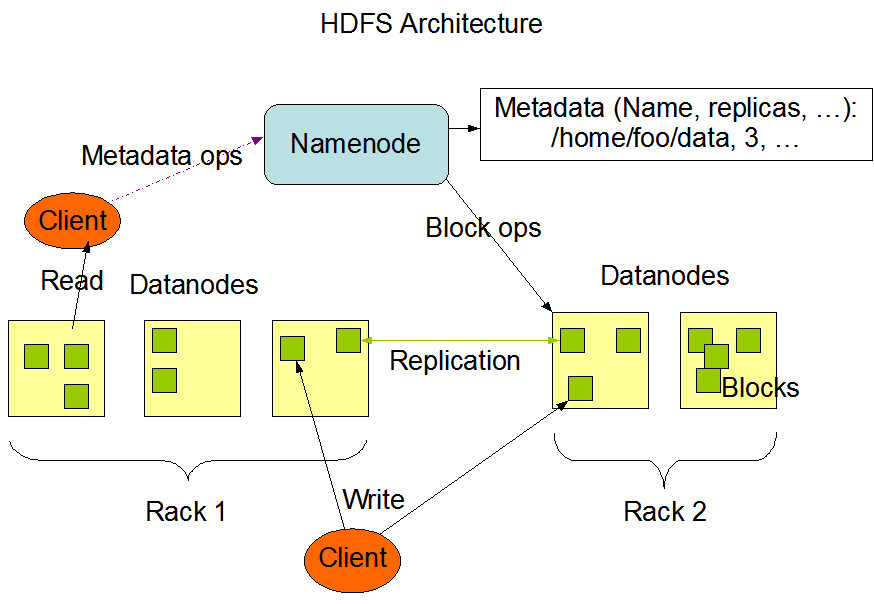
1. 架构概述
HDFS采用主从架构(Master-Slave),由一个NameNode(主节点)和多个DataNode(从节点)组成。NameNode负责管理文件系统的命名空间和客户端对文件的访问操作,而DataNode负责存储实际的数据。
2. 主要组件
(1)NameNode
- NameNode是HDFS的主节点,负责维护文件系统的命名空间。
- 它管理文件系统树及整个文件系统的元数据,但实际数据不存储在这里。
- NameNode记录每个文件的数据块映射信息,即哪个文件由哪些数据块组成,以及这些数据块存储在哪些DataNode上。
- NameNode还负责处理客户端的读写请求,协调各个DataNode之间的数据复制。
(2)DataNode
- DataNode是HDFS的从节点,负责处理文件系统客户端的读写请求。
- 它存储实际的数据块,并在NameNode的指导下执行数据块的创建、删除和复制操作。
- 每个DataNode都会定期向NameNode发送心跳信号,报告自己的状态。
以下以下是详细的架构设计部分:
3. 数据存储
(1)数据块
- HDFS将文件分割成固定大小的数据块,默认大小为128MB(Hadoop 2.x版本为128MB,3.x版本为256MB)。
- 每个数据块会有多个副本,默认为三个,以提高系统的容错性和可靠性。
(2)副本存放策略
- 副本的存放策略通常是将第一个副本放在本地DataNode上,其他副本放在其他机架的DataNode上。
4. 容错机制
(1)心跳机制
- DataNode会定期向NameNode发送心跳信号,以证明自己仍然在线。
- 如果NameNode长时间未收到某个DataNode的心跳,则认为该DataNode已经失效。
(2)数据恢复
- 当某个DataNode失效时,NameNode会指令其他DataNode复制该失效节点上的数据块,以维持副本数量。
5. 数据读写流程
(1)读数据
- 客户端向NameNode发起读请求,NameNode返回文件的数据块信息及所在DataNode的地址。
- 客户端直接与DataNode通信,读取数据。
(2)写数据
- 客户端向NameNode发起写请求,NameNode确定文件数据块的存放位置。
- 客户端将数据写入到指定的DataNode,DataNode再将数据复制到其他副本所在的DataNode。
6. 安全性
- HDFS支持Kerberos认证,确保只有授权用户才能访问文件系统。
- HDFS还支持数据传输加密,保护数据在传输过程中的安全性。
以上便是HDFS的架构设计概述。这种设计使得HDFS能够高效地处理海量数据,同时保证了高可用性、高可靠性和可扩展性。
